
这是一个创建于 2925 天前的主题,其中的信息可能已经有所发展或是发生改变。
研究了 Machine learning 中 SVM 分类器的一些简单应用,分享下研究过程。
[序言]
市场形态预测器
What
市场形态预测器:将市场分为震荡市场和趋势市场,希望能够依据历史信息判断第二天的市场为震荡市场还是趋势市场。
Why
若能够大概率下准确判断未来是震荡市场还是趋势市场,可以据此信号来做 MOM 或 FOF 等资产配置类的策略。比如在震荡市场,将资产权重更多的配置在波动率策略上;在趋势市场,将资产权重更多的配置在趋势策略上等。
How
鉴于机器学习在各领域中已经开始绽放光芒,它必然也能给金融市场带来滋养。二级市场试图做的事情无非是在历史信息中挖掘特征去拟合未来收益函数或判断离散变量。拟合未来收益函数这件事本身是比较困难的,因此判断离散变量相对来说更加务实一点,离散变量可以是涨跌,也可以是自定义的离散类别。因此个人认为 ML 对金融市场的帮助应该先从有监督的分类器入手,本文尝试使用 sklearn 中 SVM 的分类器对市场形态进行预测,给出个简单的研究过程来抛砖引玉。
[研究方法]
确定标的
标的为单只股票或指数的收盘价格时间序列。
标定数据
根据某种市场形态的定义规则来为每一天贴标签,本文中标签为二元标签『-1 :震荡市场; 1 :趋势市场』,其标定方法参考华泰联合证券之《震荡市还是趋势市?--市场状态的量化划分方法及应用》。
生成数据集
利用带标签的数据生成数据集,生成函数 f :特征向量↦标签。生成函数是 ML 的一大核心,其包括选取合适的特征及贴合适的标签(做预测器通常用 t 时刻的特征对应 t+1 时刻的标签)。
模型优化
利用交叉验证中测试集准确率的平均作为某个模型的成绩,并通过 sklearn 中的网格优化选择合适的模型。
[研究 —— 确定标的]
使用沪深 300 指数 10 年的收盘价序列进行测试
[研究 —— 标定数据]

底下代码无法转贴在 V2EX 上,感兴趣的亲请戳: https://uqer.io/community/share/5790ac2e228e5b90c1a2e2c1
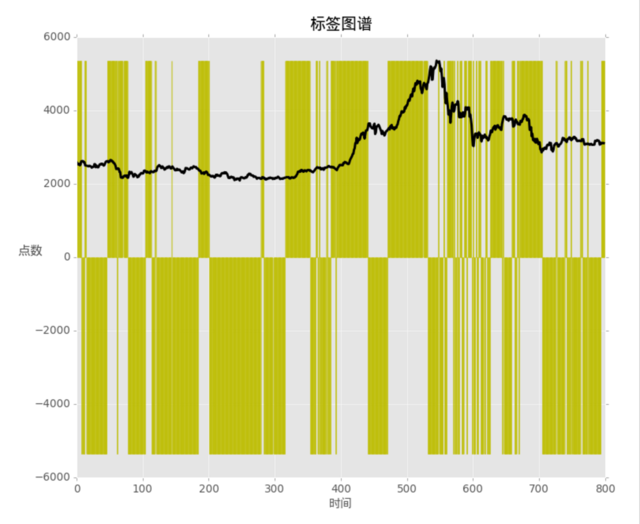
“ Market efficiency ”定义所选取的阈值为 0.199 。由上图可以看出,其标注符合预期。
[研究 —— 生成数据集]
使用了比较简单的方法生成数据集。直接将 t 日过去 n 日的时间序列作为 feature ,其后一日 t+1 的市场形态标签作为 label , 以此对应数据集。这样的思路是利用过去 n 的收盘价用作 n 个特征维度,来预测后一天的市场形态。
[研究 —— 网格优化]
利用 sklearn 中的网格优化在一定的参数范围内选取合适的模型。
代码请移步: https://uqer.io/community/share/5790ac2e228e5b90c1a2e2c1
Tips
Grid search 的原理其实是参数遍历,并返回一个 grid score 字典记录每一组组合的结果。 这个原理很简单,可以通过遍历笛卡尔积来手动实现。但利用 sklearn 的好处是其模型内部做了优化,可以配置硬件,设置缓存大小及 CPU 核。
代码请移步: https://uqer.io/community/share/5790ac2e228e5b90c1a2e2c1
以上计算出了最优的 SVC 的模型及其 10−fold 交叉验证的准确率(测试集准确预测的百分比)。
观察可知,交叉验证的结果相近,因此理论上不存在过拟合问题。
可通过设置大而密的网格,并借助硬件的力量,去训练得到性能较好的模型。
此处交叉验证的平均准确率可近似为样本外回测,但不等同。原因在于:样本外回测时,要考虑样本的时间先后性;而交叉验证的结果并不考虑样本的时间先后性。
[小结]
可利用有监督的分类器尝试做一些离散的预测信号;
对于离散的分类器模型,如 SVC , passiveAggressive, Decesion tree 等:
若训练集无序,研究中最好通过交叉验证来验证有无过拟合;
若训练集有序,研究中应尽量增大测试集的比例;
若做实时策略模型,应尽量使用 online 的学习算法。
数据集生成中,特征向量的选取可以更加精炼并有所选择。特征选取可结合无监督学习、神经网络等方法。
PS. 本文给出了研究机器学习模型的简单过程。真正实战,建议首先利用 offline 模型通过训练、优化、交叉验证对分类器的功能构想做验证,进而再开发 online 的实际策略模型,也许会更加清晰哦。
[序言]
市场形态预测器
What
市场形态预测器:将市场分为震荡市场和趋势市场,希望能够依据历史信息判断第二天的市场为震荡市场还是趋势市场。
Why
若能够大概率下准确判断未来是震荡市场还是趋势市场,可以据此信号来做 MOM 或 FOF 等资产配置类的策略。比如在震荡市场,将资产权重更多的配置在波动率策略上;在趋势市场,将资产权重更多的配置在趋势策略上等。
How
鉴于机器学习在各领域中已经开始绽放光芒,它必然也能给金融市场带来滋养。二级市场试图做的事情无非是在历史信息中挖掘特征去拟合未来收益函数或判断离散变量。拟合未来收益函数这件事本身是比较困难的,因此判断离散变量相对来说更加务实一点,离散变量可以是涨跌,也可以是自定义的离散类别。因此个人认为 ML 对金融市场的帮助应该先从有监督的分类器入手,本文尝试使用 sklearn 中 SVM 的分类器对市场形态进行预测,给出个简单的研究过程来抛砖引玉。
[研究方法]
确定标的
标的为单只股票或指数的收盘价格时间序列。
标定数据
根据某种市场形态的定义规则来为每一天贴标签,本文中标签为二元标签『-1 :震荡市场; 1 :趋势市场』,其标定方法参考华泰联合证券之《震荡市还是趋势市?--市场状态的量化划分方法及应用》。
生成数据集
利用带标签的数据生成数据集,生成函数 f :特征向量↦标签。生成函数是 ML 的一大核心,其包括选取合适的特征及贴合适的标签(做预测器通常用 t 时刻的特征对应 t+1 时刻的标签)。
模型优化
利用交叉验证中测试集准确率的平均作为某个模型的成绩,并通过 sklearn 中的网格优化选择合适的模型。
[研究 —— 确定标的]
使用沪深 300 指数 10 年的收盘价序列进行测试
[研究 —— 标定数据]

底下代码无法转贴在 V2EX 上,感兴趣的亲请戳: https://uqer.io/community/share/5790ac2e228e5b90c1a2e2c1

“ Market efficiency ”定义所选取的阈值为 0.199 。由上图可以看出,其标注符合预期。
[研究 —— 生成数据集]
使用了比较简单的方法生成数据集。直接将 t 日过去 n 日的时间序列作为 feature ,其后一日 t+1 的市场形态标签作为 label , 以此对应数据集。这样的思路是利用过去 n 的收盘价用作 n 个特征维度,来预测后一天的市场形态。
[研究 —— 网格优化]
利用 sklearn 中的网格优化在一定的参数范围内选取合适的模型。
代码请移步: https://uqer.io/community/share/5790ac2e228e5b90c1a2e2c1
Tips
Grid search 的原理其实是参数遍历,并返回一个 grid score 字典记录每一组组合的结果。 这个原理很简单,可以通过遍历笛卡尔积来手动实现。但利用 sklearn 的好处是其模型内部做了优化,可以配置硬件,设置缓存大小及 CPU 核。
代码请移步: https://uqer.io/community/share/5790ac2e228e5b90c1a2e2c1
以上计算出了最优的 SVC 的模型及其 10−fold 交叉验证的准确率(测试集准确预测的百分比)。
观察可知,交叉验证的结果相近,因此理论上不存在过拟合问题。
可通过设置大而密的网格,并借助硬件的力量,去训练得到性能较好的模型。
此处交叉验证的平均准确率可近似为样本外回测,但不等同。原因在于:样本外回测时,要考虑样本的时间先后性;而交叉验证的结果并不考虑样本的时间先后性。
[小结]
可利用有监督的分类器尝试做一些离散的预测信号;
对于离散的分类器模型,如 SVC , passiveAggressive, Decesion tree 等:
若训练集无序,研究中最好通过交叉验证来验证有无过拟合;
若训练集有序,研究中应尽量增大测试集的比例;
若做实时策略模型,应尽量使用 online 的学习算法。
数据集生成中,特征向量的选取可以更加精炼并有所选择。特征选取可结合无监督学习、神经网络等方法。
PS. 本文给出了研究机器学习模型的简单过程。真正实战,建议首先利用 offline 模型通过训练、优化、交叉验证对分类器的功能构想做验证,进而再开发 online 的实际策略模型,也许会更加清晰哦。
 |
1
t6attack 2016-11-28 17:32:36 +08:00
此文一句话也没看懂。不过, libsvm 在实际编程中用好久了。
|
 |
2
uuuing 2016-11-28 17:39:24 +08:00
没听懂 感觉很高大上。。
|
 |
3
kyy531366925 2016-11-28 18:46:31 +08:00
正在自学 ML
|